OpenStack ist eine der führenden Open-Source-Plattformen für die Bereitstellung und den Betrieb von Cloud-Infrastrukturen. Ein zentraler Aspekt bei der Nutzung von Cloud-Ressourcen ist das Verständnis und Management der Kosten, die dabei entstehen. In diesem Beitrag zeigen wir, warum gestoppte Instanzen weiterhin Kosten verursachen und wie das Shelving von Instanzen diese Kosten beeinflussen kann.
OpenStack Dienste & Starten von Instanzen
Das Bereitstellen und Verwalten von Instanzen übernimmt der Dienst OpenStack Compute, auch Nova genannt. Die Nova REST API ist der zentrale Einstiegspunkt über die OpenStack CLI oder die grafische Benutzeroberfläche, dem Dashboard. Für das eigentliche Erstellen einer Instanz werden jedoch auch weitere OpenStack-Dienste einbezogen, beispielsweise Placement für die Verwaltung des Ressourcenbestandes, Glance als Image Service oder Cinder zur Bereitstellung von Volumes. [1]
Die Begriffe Launch und Start werden in diesem Zusammenhang gelegentlich synonym verwendet, bezeichnen jedoch unterschiedliche Prozesse. Der Launch einer Instanz beschreibt den gesamten Prozess des Erstellens inklusive dem Start einer Instanz. Dieser Prozess erfolgt entweder über die OpenStack CLI mit dem Befehl openstack server create oder über das Dashboard. An dieser Stelle sei auch auf den Blogpost „Create a Network in OpenStack“ verwiesen. Dort wird nach der initialen Netzwerkkonfiguration eine Instanz erstellt, die ein Ubuntu Image auf Ephemeral Storage installiert. Dieser lokale Speicher wird direkt auf dem Hypervisor bereitgestellt und ermöglicht schnelle Speicherzugriffe und geringere Latenzen gegenüber der Verwendung von Cinder-Volumes [2]. Allerdings ist dieser Speicher weder persistent, noch über mehrere Verfügbarkeitszonen hinweg repliziert. Folglich gehen diese Daten beim Löschen der Instanz verloren und sind beim Ausfall des entsprechenden Hosts mindestens temporär nicht verfügbar. Um dieses Szenario zu adressieren, bietet unsere Cloudumgebung einen dreifach replizierten Block-Storage mit unterschiedlichen Storageklassen. So ist es möglich, bootbare Volumes zu erstellen oder nicht-bootbare Volumes an bestehende Instanzen anzuhängen:
openstack server create – Parameter | Verwendung |
|---|---|
--block-device <Block-Device-Mapping-v2> | z. B. ein nicht-bootbares Volume anhängen [3] |
--image <id-or-name> und --boot-from-volume <size> | Ein bootbares Volume aus einem Image erstellen |
--volume <id-or-name> | Ein bestehendes bootbares Volume anhängen |
Die Instanz befindet sich anschließend im Status ACTIVE und nach dem Stoppen im Status SHUTOFF. Statuswechsel durch Events, wie zum Beispiel start, stop oder delete, werden von OpenStack Nova pro Instanz aufgezeichnet und können entweder mit openstack server event list <instance> oder im Action Log der Instanz im Dashboard eingesehen werden.
Lebenszyklus einer Instanz
Der Lebenszyklus einer Instanz umfasst den Zeitraum, in dem Kosten in Höhe des gewählten Flavors anfallen [4]. Dieser beginnt mit dem Event create. Dabei werden Ressourcen wie CPU, Arbeitsspeicher und Speicherkapazität gemäß der gewählten Flavordefinition allokiert. Diese Ressourcen bleiben in der Regel bis zum Ende des Lebenszyklus, also bis zu einem delete-Event, reserviert.
Das bedeutet, dass auch das Pausieren, Stoppen oder Anhalten von Instanzen mit den Events pause, stop oder suspend nicht dazu führt, dass die Ressourcen freigegeben werden. Dies geschieht in der Annahme, dass eine gestoppte Instanz nur temporär nicht verwendet und nach kurzer Zeit wieder gestartet wird. Dadurch ist sichergestellt, dass die Ressourcen für eine Nutzung reserviert bleiben und die zugehörigen Events unpause, start und resume nicht aufgrund fehlender Compute-Ressourcen fehlschlagen. Da reservierte Ressourcen nicht von anderen Instanzen nutzbar sind, werden diese Kosten kontinuierlich abgerechnet.
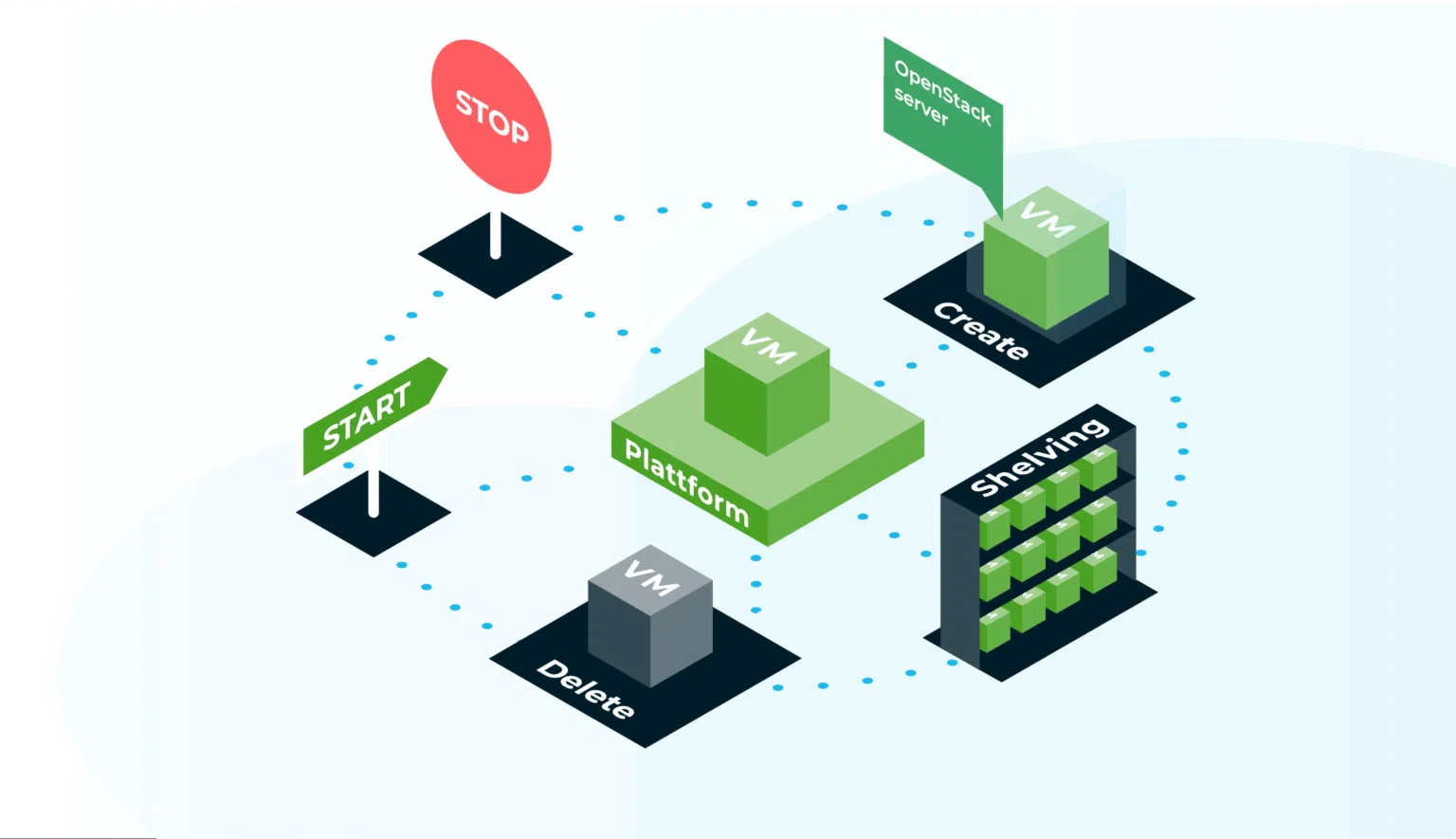
Shelving: Ressourcen freigeben & Zustand bewahren
Eine Möglichkeit Ressourcen in OpenStack freizugeben ohne eine Instanz löschen zu müssen, bildet das Shelving von Instanzen via openstack server shelve <instance>. Dieses erlaubt das Stoppen und Persistieren einer Instanz, ohne weiterhin Compute-Ressourcen auf dem Hypervisor zu reservieren. Eine solche sich im Status SHELVED_OFFLOADED befindende Instanz verwirft zwar sämtliche RAM-Inhalte, persistiert jedoch den Zustand der verwendeten Root-Disk. Durch die zwischenzeitlich freigegebenen Compute-Ressourcen entstehen für die Dauer des SHELVED_OFFLOADED Zustands lediglich Kosten in Höhe des belegten Storage. Auch in diesem Zustand werden die Compute-Ressourcen auf das verfügbare Kontingent, die Quota, angerechnet. Der Ablauf des Shelvings variiert je nach Art des Datenträgers: Wenn die Root-Disk als Ephemeral Storage vorliegt, wird ein Snapshot in die Glance-Image-Library geladen und anschließend der Ephemeral Storage gelöscht. Beim Löschen der Instanz wird auch der zugehörige Image-Snapshot gelöscht. Liegt die Root-Disk dagegen in Form eines Cinder-Volumes vor, so muss kein Snapshot erzeugt werden, da der Disk-Zustand in diesem Volume bereits persistiert ist. Wird die Instanz gelöscht, bleibt das Volume standardmäßig erhalten. Solche Instanzen werden demnach auch als volume backed bezeichnet. [5]
In beiden Fällen gilt: Bei Bedarf lässt sich die Instanz mit openstack server unshelve <instance> wieder bereitstellen. Sie wird dabei jedoch nicht automatisch dem ursprünglichen Hypervisor zugeordnet. Das Shelving von Instanzen deren Root-Disk nicht in einem Volume liegt, kann je nach Größe eine signifikante Zeitspanne beanspruchen, da während dieses Vorgangs Konvertierungsprozesse erfolgen und die Daten in das Storage-Backend übertragen werden. Das Shelving einer Instanz, deren Root-Disk bereits auf einem Volume liegt, erfolgt hingegen nahezu unverzüglich. Für eine On-Demand-Nutzung von Cloud-Ressourcen kann der Einsatz eines bootbaren Volumes als Root-Disk entsprechende Vorteile bieten. Die Cinder-Volumes können über verschiedene Storage-Klassen mit unterschiedlicher Performance bereitgestellt werden. Gerne unterstützen wir Sie bei der Auswahl, je nach Ihrem individuellen Anwendungsszenario.


")